Reading and summarizing books on lean software development, so you dont have to. Part 3 (see Part 1 and Part 2).
“Implementing Lean Software Development” written by Mary and Tom Poppendieck and published 2007 at Addison-Wesley. The Poppendiecks are quite famous in the lean-agile software development community, as they published the constitutive book „Lean Software Development: An Agile Toolkit“ in 2003, the first (recognized) book about bringing the lean principles to the software development space. The book reviewed here is a successor book aimed at delivering more practical advice. As in the last parts, my review will not focus on re-iterating lean and agile fundamentals, but rather focus on novelty aspects, ideas, and noteworthy pieces.
In the foreword, Jeff Sutherland (co-founder of the Scrum framework) introduces the Japanese terms of Muri (properly loading a system), Mura (never stressing a person, system or process) and Muda (waste):
Yet many managers want to load developers at 110 percent. They desperately want to create a greater sense of “urgency” so developers will “work harder.” They want to micromanage teams, which stifles
page xix
self-organization. These ill-conceived notions often introduce wait time, churn, death marches, burnout, and failed projects.
When I ask technical managers whether they load the CPU on their laptop to 110 percent they laugh and say, “Of course not. My computer would stop running!” Yet by overloading teams, projects are often late, software is brittle and hard to maintain, and things gradually get worse, not better.
In their historical review the authors bring a very interesting statistics which should resonate with many of my peers:
Both Toyodas had brilliantly perceived that the game to be played was
page 5
not economies of scale, but conquering complexity. Economies of scale will reduce costs about 15 percent to 25 percent per unit when volume doubles. But costs go up by 20 percent to 35 percent every time variety doubles. Just-in-Time flow drives out major contributors to the cost of variety. In fact, it is the only industrial model we have that effectively manages complexity.
As evidence, two papers are given: „Time -The Next Source of Competitive Advantage“ by George Stalk and „Lean or Sigma?“ by Freddy and Michael Balle. Managers and engineers increasingly become aware about the not-so-visible cost of complexity, typically by experiencing project failure or long-term product degradation.
For the aspect of inventory, the authors provide a quite good methaphor:
Inventory is the water level in a stream, and when the water level is high, a lot of big rocks lurking under the water are hidden. If you lower the water level, the big rocks begin to surface. At that point, you have to clear the rock out of the way, or your boat will crash into them. As the big rocks are removed, you can lower inventory level some more, find more rocks, clear them out of the stream, and keep on going until there are just pebbles left.
page 8
That adoption of lean practices and mindset is not straightforward and many organizations struggle or fail to do so is explained by the authors by pointing at a „cherrypicking“ approach. Hence, only some activities of the lean domain are adopted in isolation, like just-in-time or stop-the-line. Instead, they a classic:
The truly lean plant […] transfers the maximum number of tasks and responsibilities to those workers actually adding value to the car on the line, and it has in place a system for detecting defects that quickly
Womack, Jones, Roos: The machine that changed the world, page 99
traces every problem, once discovered, to its ultimate source.
I think this cannot be underestimated. To seldom I have seen organizations and management really focussing on the „value creators“ and the impediments those are facing.
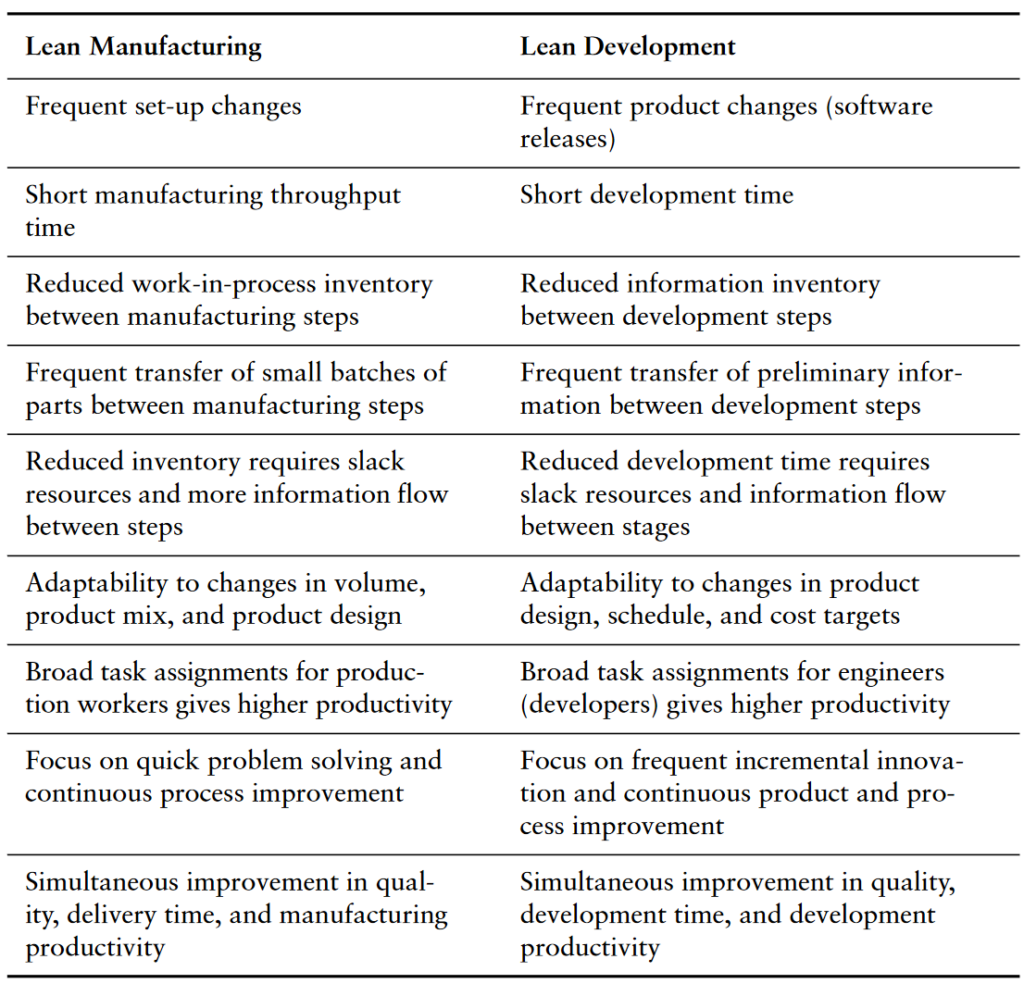
In earlier blog posts I already wrote about the differences and similarities in the lean manufacturing and lean development. The Poppendiecks provide a table putting both side-by-side (page 14):
Later, in a footnote, the authors refer to a paper by Kajko-Mattsson et al. on the cost of software maintenance. The paper’s sources vary a lot, however its obvious that considering a typical big software project it becomes clear that this ratio quickly translates to millions of Euro/Dollar.
The published numbers point out that maintenance costs between 40% to 90% […]. There are very few publications reporting on the cost of each individual maintenance category. The reported ones are the
Kajko-Mattsson et al: Taxonomy of problem management activities, page 1
following: (1) corrective maintenance – 16-22% […] (2) perfective maintenance – 55% […], and (3) adaptive maintenance – 25% […].
On the lean principle of waste, the Poppendiecks make a simple but revelating statement:
To eliminate waste, you first have to recognize it. Since waste is anything
page 23
that does not add value, the first step to eliminating waste is to develop a keen sense of what value really is. There is no substitute for developing a deep understanding of what customers will actually value once they start using the software. In our industry, value has a habit of changing because, quite often, customers don’t really know what they want. In addition, once they see new software in action, their idea of what they want will invariably shift. Nevertheless, great software development organizations develop a deep sense of customer value and continually delight their customers.
Too often have I experienced software development projects who dont know what their product and the value they provide actually is. Of course, everyone has a vague feeling about what it could be, but putting it in clear words is seldom attempted and easily ends in conflict (a conflict which can be constructive if facilitated well).
On the second principle „Build Quality In“, there are some interesting distinctions on defects and the relation to „inspection“:
According to Shigeo Shingo, there are two kinds of inspection: inspection after defects occur and inspection to prevent defects.10 If you really want quality, you don’t inspect after the fact, you control conditions so as not to allow defects in the first place. If this is not possible, then you inspect the product after each small step, so that defects are caught immediately after they occur. When a defect is found, you stop-the-line, find its cause, and fix it immediately.
page 27
Defect tracking systems are queues of partially done work, queues of rework if you will. Too often we think that just because a defect is in a queue, it’s OK, we won’t lose track of it. But in the lean paradigm, queues are collection points for waste. The goal is to have no defects in the queue, in fact, the ultimate goal is to eliminate the defect tracking queue altogether. If you find this impossible to imagine, consider Nancy Van Schooenderwoert’s experience on a three-year project that developed complex and often-changing embedded software. Over
the three-year period there were a total of 51 defects after unit testing with a maximum of two defects open at once. Who needs a defect tracking system for two defects?
The authors are citing two papers by Nancy Van Schooenderwoert („Taming the Embedded Tiger – Agile Test Techniques for Embedded
Software“ and „Embedded Agile Project by the Numbers With Newbies„). This resonates well with me, because accumulating too many defect (tickets) is very expensive waste. Its a kind of inventory with the worst properties. To break out of this is not straightforward, I have attempted and failed multiple times to establish a „zero defect policy“ (i.e. as long as there is a defect no further feature development happens). In that context let me at two more quotes from the book:
The job of tests, and the people that develop and runs tests, is to prevent defects, not to find them.
page 28
“Do it right the first time,” has been interpreted to mean that once code is written, it should never have to be changed. This interpretation encourages developers to use some of the worst known practices for the design and development of complex systems. It is a dangerous myth to think that software should not have to be changed once it is written.
page 29
On the fifth principle of „Deliver Fast“ a very important statement is made:
Caution: Don’t equate high speed with hacking. They are worlds apart. A fast-moving development team must have excellent reflexes and a disciplined, stop-the-line culture. The reason for this is clear: You can’t sustain high speed unless you build quality in.
page 35
Very often I observe a dire need for speed. Of course everyone wants to be faster in the software industry. Competition doesnt sleep. However, similar to unclear definitions of value and products, I have barely ever seen a clear definition of speed in a software project. Or, probably more correct: there were competing definitions of speed on people’s and especially decision maker’s minds. Its a huge difference to beat your team to „push out features now“ and grind to a halt when quality activities are started, or to maintain a sustainable pace:
When you measure cycle time, you should not measure the shortest time through the system. It is a bad idea to measure how good you are at expediting, because in a lean environment, expediting should be neither necessary nor acceptable. The question is not how fast can you deliver, but how fast do you repeatedly and reliably deliver a new capability or respond to a customer request.
page 238
The Poppendiecks are summarizing those effects in two vicious cycles (page 38):


For all the lean principles, the Poppendiecks also discuss myths originating from mis-interpreting the principles or applying them wrongly. One which caught my attention was the myth „Optimize by decomposition“. Its about the proliferation of metrics once an organization starts to apply the benefits of visual management. All of a sudden, there are tens if not hundreds of dashboards, graphs, KPIs, and such flying around. Their recommendation:
When a measurement system has too many measurements the real goal of the effort gets lost among too many surrogates, and there is no guidance for making tradeoffs among them. The solution is to “Measure UP” that is, raise the measurement one level and decrease the number of measurements. Find a higher-level measurement that will drive the right results for the lower level metrics and establish a basis for making trade-offs.
page 40
Speaking about myths, they encourage readers to check which myths apply to their situation – certainly a worthwile exercise also for you 🙂
Early specification reduces waste
page 42
The job of testing is to find defects
Predictions create predictability
Planning is commitment
Haste makes waste
There is one best way
Optimize by decomposition
Coming back to the notion of value, the authors are asking the fundamental question how great products are conceived and developed. They write:
In 1991, Clark and Fujimoto’s book Product Development Performance presented strong evidence that great products are the result of excellent, detailed information flow. The customers‘ perception of the product is determined by the quality of the flow of information between the marketplace and the development team. The technical integrity of the product is determined by the quality of the information flow among upstream and downstream technical team members. There are two steps you can take to facilitate this information flow: 1) provide leadership, and 2) empower a complete team.
page 52
The book has an extensive chapter on waste with many insightful aspects. I dont want to repeat all of them, and instead just provide some examples. For example I found this statement on the relationship of automation and waste/complexity very inspiring.
We are not helping our customers if we simply automate a complex or messy process; we would simply be encasing a process filled with waste in a straight jacket of software complexity. Any process that is a candidate for automation should first be clarified and simplified, possibly even removing existing automation. Only then can the process be clearly understood and the leverage points for effective automation identified.
page 72
In my current position, automation is a key activity, and we try to automate everything in an endeavour to increase speed, quality and convenience. The quote points out, that automation can hide or defer complexity. I can confirm this. Even though my team automated the complexity of product variants in the build process, our customers (e.g. manual testers) dont have a chance to test all the build we produce. Hence, even made with best intentions, our automation is overloading the whole.
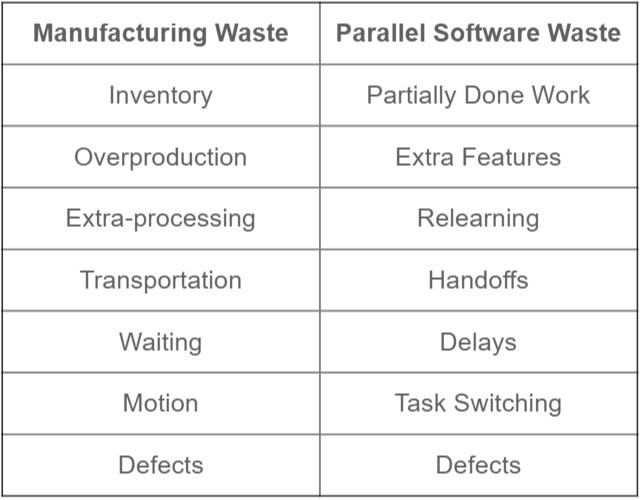
Another good comparison between traditional manufacturing and software development is the following table, putting the seven waste equivalents side-by-side (page 74):
On architectural foresight, I like the following statement:
Creating an architectural capability to add features later rather than sooner is good. Extracting a reusable services „framework“ for the enterprise has often proven to be a good idea. Creating a speculative application framework that can be configured to do just about anything has a track record of failure. Understand the difference.
page 76
While discussing Value Streams, the authors dig into effectiveness and efficiency. They are of the opinion that
chasing the phantom of full utilization creates long queues that take far more effort to maintain than they are worth-and actually decreases effective utilization.
page 88
This opinion is not speculation, they provide a good analogy to road traffic and computer utilization:
High utilization is another thing that makes systems unstable. This is obvious to anyone who has ever been caught in a traffic jam. Once the utilization of the road goes above about 80 percent, the speed of the traffic starts to slow down. Add a few more cars and pretty soon you are moving at a crawl. When operations managers see their servers running at 80 percent capacity at peak times, they know that response time is beginning to suffer, and they quickly get more servers. […]
Most operations managers would get fired for trying to get maximum utilization out of each server, because it’s common knowledge that high utilization slows servers to a crawl. Why is it that when development managers see a report saying that 90 percent of their available hours were used last month, their reaction is, „Oh look! We have time for another project!“
pages 101f
I think in daily work, management typically does not pay enough attention to those basics. It is not that this is not known that too high utilization of resouces is bad, quite the opposite is the case in my experience. However, the root causes and the remedies are often not considered. Instead, there is a sentiment of capitulation: „Yes I know our team is stressed and overloaded, but we have to get faster nevertheless.“
In order to reduce cycle times, the authors refer to queuing theory, which provides several approaches:
Even out the arrival of work
Minimize the number of things in process
Minimize the size of things in process
Establish a regular cadence
Limit work to capacity
Use pull scheduling
page 103
In the chapter „People“, there is a lot of reference to William Edwards Deming, a pioneer of quality management. Its an iron of history, that this American actually was teaching the fundamentals of what leater became Lean in post-war Japan, while he was „discovered“ only in the 1980s by the US (industrial) public. Deming formulated a what he called „System of Profound Knowledge“:
https://medium.com/10x-curiosity/system-of-profound-knowledge-ce8cd368ca62
- Appreciation of a System: A business is a system. Action in one part of the system will have effects in the other parts. We often call these “unintended consequences.” By learning about systems we can better avoid these unintended consequences and optimize the whole system.
- Knowledge of Variation: One goal of quality is to reduce variation. Managers who do not understand variation frequently increase variation by their actions. Critical to this is understanding the two types of variation — Common cause which is variation from the system and Special cause which variation from outside the system
- Theory of Knowledge: There is no knowledge without theory. Understanding the difference between theory and experience prevents shallow change. Theory requires prediction, not just explanation. While you can never prove that a theory is right, there must exist the possibility of proving it wrong by testing its predictions.
- Understanding of Psychology: To understand the interaction between work systems and people, leaders must seek to answer questions such as: How do people learn? How do people relate to change? What motivates people?
When pursuing change and transformation, it is very important to take the staff on board. This is easier said than done, because the employees have a very fine sense. They realize very quickly, if for example a certain change in mindset is requested from them, but not exercised by their supervisors. In engineering projects, the demands and expectations of decision makers are often antagonistic to their communicated strategies and visions. Just consider if in your organization „quality“ is an essential part of your long-term goals, and totally overriden by daily task force death marches.
The challenge to achieve quality is handled in another dedicated chapter. The authors point out the importance of „superb, detailed discipline“ to achieve high quality. Here come the famous „5 S’s“ into play. The book’s authors transfer them also to the software space:
Sort (Seiri): Sort through the stuff on the team workstations and servers, and find the old versions of software and old files and reports that will never be used any more. Back them up if you must, then delete them.
Systematize (Seiton): Desktop layouts and file structures are important. They should be crafted so that things are logically organized and easy to find. Any workspace that is used by more than one person should conform to a common team layout so people can find what they need every place they log in.
Shine (Seiso): Whew, that was a lot of work. Time to throw out the pop cans and coffee cups, clean the fingerprints off the monitor screens, and pick up all that paper. Clean up the whiteboards after taking pictures of the important designs that are sketched there.
Standardize (Seiketsu): Put some automation and standards in place to make sure that every workstation always has the latest version of the tools, backups occur regularly, and miscellaneous junk doesn’t accumulate.
Sustain (Shitsuke): Now you just have to keep up the discipline.
page 191
I really enjoyed reading this book and can absolutely recommend reading it. It contains a lot of gems, and is probably one of those book you want to read every other year again to re-discover aspects and connect them to new experience.