(Disclaimer: As usual, I am writing here from the perspective of my personal, automotive embedded sw perspective. Below are my thoughts based on everyday-experience as an engineering manager and sw enthusiast. I am not a trained/certified test expert with deep knowledge in testing theory/science, frameworks and terminology. Please take it with a grain huge truckload of salt. Let me know your opinion!)
Introduction
After more than 17 years in automotive sw engineering, I have come to see testing as an integral part of everyday sw engineering practice. At first, such a statement seems obvious – it doesnt need 17 years to understand the importance of testing. True, but read the italic sentence again. I wrote „part of everyday […] practice“. To a suprise for some, and bitterly confirming others, this is not the case up until today in many automotice sw projects. Testing is often decoupled in various dimensions:
Testing is done much later than the code implementation (weeks, months, years)
Testing is executed when big SW releases are made (think: on a monthly or quarterly scale)
Testing is done to satisfy some process requirements (again, usually late, briefly before start of production)
Testing is done by dedicated staff in testing organizations, spacially and organizationally decoupled from the other sw roles (architects, programmers, Product Owners)
Even when talking about the lowest tier of sw testing, unit testing and coding rule compliance, much if not all of the above applies. When it comes to higher levels of testing such as integration testing or qualification testing, more and more of the above list applies.
There are many reasons why the above is bad and why it is the case. Many such issues are based on wrong mindset and corporate organizational dynamics (e.g. the infamous „make testers a shared resource decoupled from dev teams“). Those are causes I dont want to write about today. I have done so in the past and may do in the future. My focus today is on the technical meta aspects of getting testing into the right spot.
My observation is that automotive sw testing is still in a severe lack of alignment/harmonization of the test environments. While there are many sophisticated tools serving specific purposes, the overall landscape is fragmented. Many expensive, powerful domain-specific tools are combined with home-grown tooling, resulting in test ecosystems which work all by themselves, and not leveraged for cross-domain or cross-project synergies.. Now, everyone always strives to harmonize and standardize solutions, but seldom it works out. There are a lot of organizational inertia and technical challenges, so just demanding or proclaiming a standardization often does not happen at all, or if it does, it leads to situations like my all-time favorite xkcd refers to:
However, that doesn’t mean we should die before the battle. We should be clever about our approach, and balance effort vs. (potential) value. And as we know the test ecosystem is complex, we need to make up our mind where to invest. Just throwing money and hours at „testing“ will not make anything better.
A Mental Model of Testing Aspects
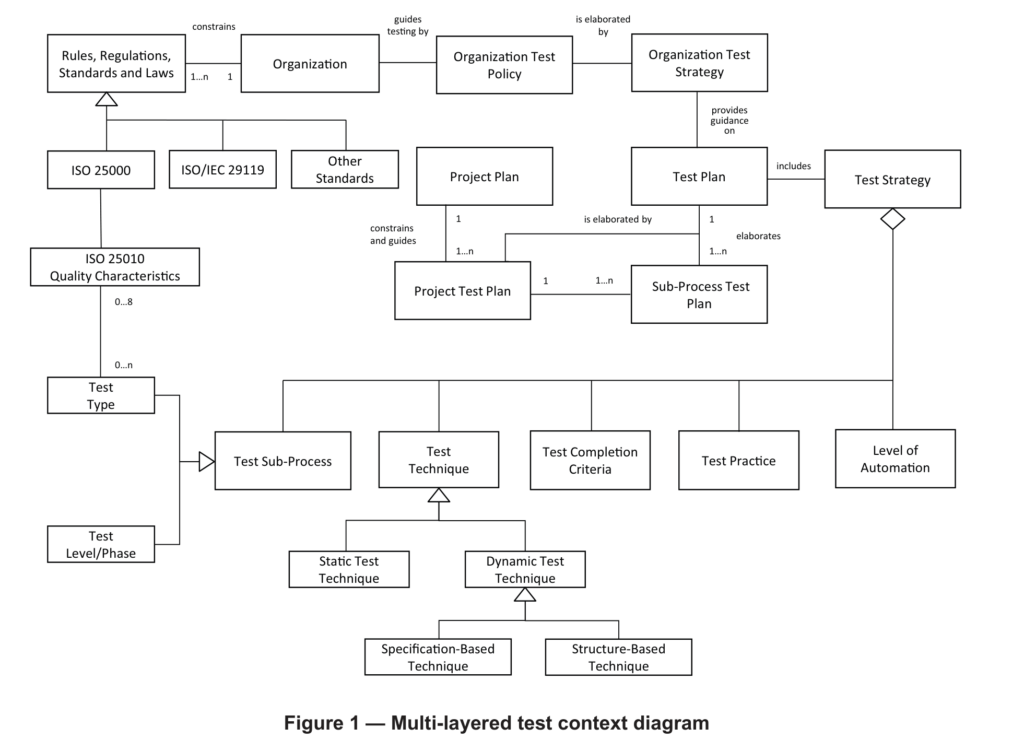
In order to see where harmonization gives the biggest bang for the buck, first we need to understand how modern testing is actually cut into pieces. I did some research and was pretty surprised that there isn’t any good model or taxonomy of testing yet described. Probably I just couldn’t find it. What one can find many times are categorizations of test types, like found here. The ISO/IEC/IEEE 29119-1 software testing standards also doesn’t really provide such a model. There is a „multi-layered test context diagram“, but it falls short in the areas where I think alignment can happen the best.
ISO/IEC/IEEE 29119-1, page 16
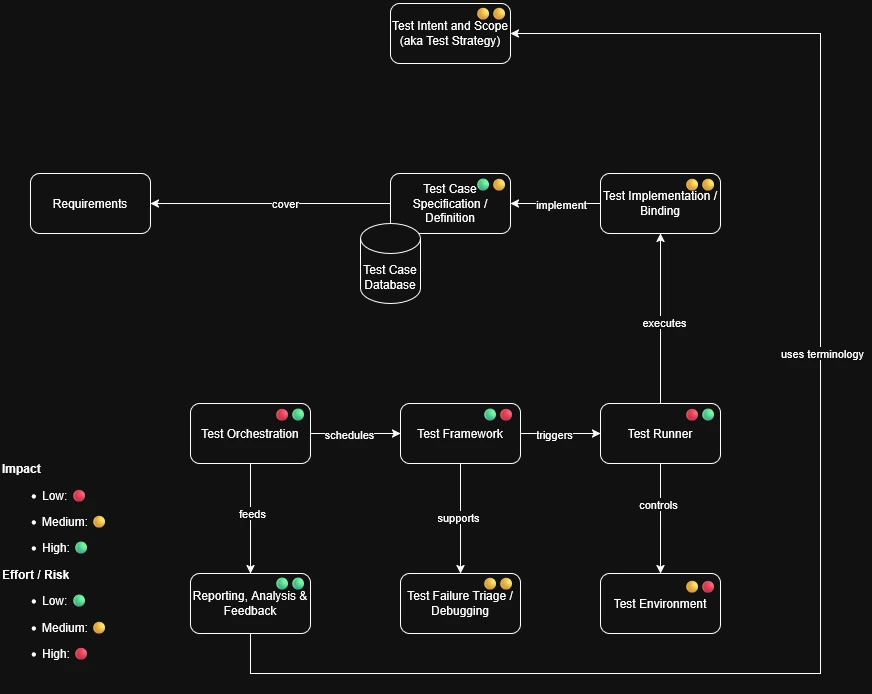
So without further ado, lets dive into my personal mental meta testing model, going from top to bottom or from outside in. And what opportunities to align and harmonize do each offer.
1. Test Intent and Scope (aka Test Strategy)
Scope: The test strategy serves to define which quality attributes are being validated by testing in a project. It can go from the classics functional correctness, interface behavior (integration testing), regression avoidance, performance to reliability, security, safety, compliance, usability, compatibility, and so on. An obvious demand by ASPICE and the like, a test strategy is often at the core of each process audit.
Pragmatic opportunities for cross-project alignment: Having contributed to test strategies written from (almost) scratch multiple times and seeing all the blood, sweat and tears flowing into it and, especially, refining and establishing it, I think the greatest opportunity here is to provide templates and knowledge:
A common template gives the responsibles a skeleton which allows them to fill in the needed parts, and all „empty“ sections are a checklist.
Besides a template, some example test strategies which passed audits are extremely helpful. If you are like me, you often wonder in which depth one shall go for a certain aspect. Shall I write a oneliner or does it require multiple pages of text with nicely crafted graphics? Examples can help to find the sweet spot of „just enough“.
Talking about examples, best practices are extremely valuable and a shared body of knowledge can bring a struggling organization from zero to hero. All it requires is to overcome the not-invented-here syndrom. There is so much good stuff out there, even in your org. You just gonna have to find it.
While the test strategy can be authored with any reasonably capable text editing format (Microsoft Word, Atlassian Confluence, …), what I have come to appreciate is using lightweight markup languages like Markdown or Sphinx. They enable handling the document as code, version track it and, ideally, even maintain alongside the actual project code.
2. Test Case Specification / Definition
Scope: Defines what the test is in an abstract sense. Each test case is described in a structure, which contains preconditions, input/stimuli, and expected outputs. Here, tracability to requirements, risks, code, variants and equivalence classes are documented. Last, but operationally very relevant are the metadata for each test case, like its priority, tags, ownership, status, etc.
Pragmatic opportunities for cross-project alignment:
Test cases should be maintained in an accessible database. Like any good software culture, the test cases should be as widely shared among testers from different projects as code is shared between software developers. As above, I think such a database is ideally done via plain text formats. If this is not an option, make sure to get your tester’s and developer’s input on the proper tool choice. A bad tool choice can severely impact testing operations and cost a lot of sunk money – I can speak from experience.
Test cases should be written with as low as possible depedency on following process steps (like test frameworks and test tooling). This makes them reusable, but also decouples them from their implementation and execution, allowing for an exchange in the tooling.
The representation of each test case should be via structured text. Natural language can be used in comments, but only structured text can be parsed in precise manner (LLMs could change this on the long run, but not yet).
Scope: Maps abstract test case specification to executable behavior. Here it usually gets very tooling specific. Here is, where APIs are implemented and keywords are bound to code (e.g. a „connect“ from step 2 is mapped to „ssh root@192.168.0.1“). A lot of efforts are spent on test setup and teardown to prepare and cleanup.
Pragmatic opportunities for cross-project alignment:
A strong culture of reusable test implementation needs to be established here. E.g. setting up the test environment can – and often is done – via very hacky means. Using established and well-maintained patterns helps.
Define an explicit „test contract“: For each test, or your whole test set/suite, explicit state which guarantees they can uphold: Test X guarantees: - deterministic result under condition Y - idempotent execution - no persistent state
Keep Environment Knowledge Out of Tests: Tests should not know URLs, credentials, ports, hardware topology
Some deeper technical topics:
Invert control of assertions and actions. Instead of hard-coding test tooling specific instructions like assert response.status_code == 200 # pytest-specific semantics use an abstraction to define what a positive response means: test.assert.status_ok(response) # test.assert.* is our own abstraction
Don’t import test environment specifics in your immediate test implementation, only in the adapters.
Seperate the „What“ from the „How“ using capability interfaces.
Make test steps declarative, not procedural. Good example: - action: http.request method: GET url: /health expect: status: 200
Centrealize test utilities as products, not helpers. Maintain them with semantic versioning.
Decouple test selection from test code. Instead of pytest tests/safety/test_error_management.py prefer run-tests --tag safety --env TEST This is extremely powerful, as it enables test selection in a metadata-driven fashion.
Ultimately, accept that 100% tool independence is a myth — design for easy replaceability. The goal is not “tool-free tests”, but cheap tool replacement. Success criteria could be that tool-specific code <10–20% of total test code, switching a runner requires new adapter, not rewriting tests and new project reuses 70–90% of test logic.
4. Test Framework
Scope: The test framework provides the strcuture for test implementation. It does so by managing the test execution lifecycle, providing fixtures (a fixture sets up preconditions for a test and tears them down afterward), enables mechanisms for parameterization and provides reporting hooks. It can also manage failure semantics, like retry on fail or handling flakiness. There are many test frameworks out there, some of them somewhat locked in to a specific programming language and test level (pytest, JUnit, gtest), others are versatile and independent (Cucumber, Robot Framework).
Pragmatic opportunities for cross-project alignment: In my experience, there are far too many test framework in use in multi-project organizations. Often, historical developments have led test frameworks being adopted. On top, test frameworks are often in-house developed as either existing ones are unknown or lacking needed functionality (or not-invented-here hits). The opportunity here is both obvious, yet hard to retrieve: Forcing multiple projects/sub-organizations to drop their beloved test framework in order to adopt another one defined centrally will cause a lot of frustration and lead to temporary loss of pace. On the other hand, strategically, it makes total sense to nourish an iterative harmonization. If you want to go for this path, I recommend to chose either an open source solution or a home-grown solution managed in an inner source fashion. While there may be attractive and powerful proprietary solutions on the market, by experience such will always have a harder time for long-term adoption. Topics like license cost, license management, improvements will always be a toll, causing friction and making dev teams seek for other solutions, again.
Adding some highly personal opinion, any test framework which wants to prevail on the long-term has to have at least following properties:
Run on Linux
Run in headless fashion (no clunky GUI)
Fully automatable
Configuration as code
No individual license per seat (so either license free, or global, company-wide license)
The above properties are not meant to be exclusive, if a tool also supports Windows and has an optional GUI, thats ok. But there is no future in that, and it actively hinders adoption.
5. Test Runner
Scope: Executes tests in a concrete process. A test runner can resolve the execution order (e.g. if test Y depends on test X), parallelize tests on one test target (if possible), manage timeouts, isolates processes and collects the test results. Runners are often stateless executors.
Pragmatic opportunities for cross-project alignment: Test frameworks often (always?) bring their test runners with them. The same observation from the Test Framework section applies here: instead of tightly coupling runners to frameworks, consider decoupled runners using containerization.
6. Test Environment
Scope: Defines where the tests run. While the test runner is typically just a tool which executes instructions on a test environment, the test environment itself defines the test execution environment: Which product targets (ECU variant X, Hardware revision Y, …), Simulators, cloud vs. on-premise, network topology, test doubles (mocks, stubs). Important aspects to cover here are provisioning (how is test software deployed = flashed?), which configuration needs to be applied to get to a running test environment, lifecycle management.
Pragmatic opportunities for cross-project alignment: Managing test environments can be very domain-specific. Often its done by documentary means, like big Excel tables containing variant information about a ECU test fleet in the lab. Applying infrastructure as code solutions like Ansible can help to create reproducible, scalable and reliable test environments. Going one step further, one may adopt managed test fleets like AWS Test Farm or use solutions like OpenDUT.
7. Test Orchestration
Scope: Coordinates what runs, when, and where. I think test orchestration is an underestimated portion of the whole. Often people don’t even realize its existence. In its simplest form, a nightly cronjob or jenkins pipeline which runs executes some tests is a test orchestration. However, a pretty unsophisticated one. Test orchestration in a more capable form can:
Distribute execution to multiple test runners/targets
Handle dependencies (above individual test case scale, see test runner)
Schedule test execution
Automatically quarantine test runners/targets (e.g. in case of failure)
Test orchestration is a central coordination layer, and therefore, extremely important in diverse tool landscape, as it enables tool mixing.
As mentioned, often CI pipelines are used for test orchestration. Another solution is LAVA. And of course, again, your choice of in-house solution.
Pragmatic opportunities for cross-project alignment: I would say, a test orchestration solution is nothing which should be harmonized with priority. Its better to focus on other parts of this model for alignment efforts. Why? While test orchestration is important and extremely helpful, having same test orchestration across many projects is rather the endgame than the starting phase. Having that said, if the testing community can agree on a common test orchestration approach early on, why not.
8. Test Failure Triage / Debugging
Scope: A grayzone in the scope of testing is the handle of failures beyond merely reporting them. While I would agree, its not formally part of testing scope, it certainly requires tester contribution in a cross-functional engineering team.
Pragmatic opportunities for cross-project alignment: While debugging a specific bug tends to be pretty project-specific, I still see opportunities for the sharing of knowledge and best practices how exactly to combine testing with debugging efforts:
How to make logs and traces available. I am seeing test activities which barely provide no logs about a failure (one extreme) to a plethora of logs potentially overwhelming the debugger (other extreme). Finding the right balance in between those extremes requires experience and experimentation. Cross-project best practice sharing can improve the maturity curve here.
Accessibility of logs is very important. There is a difference if all the logs are well accessible with one link, nicely structured in an overview, or if the logs have to be pulled via 4 different storage services with different user access mechanisms.
LLMs seem to have a lot of potential. We are still in an early phase here, and its clear that beyond trivial bugs* you cannot just throw logs at an LLM and expect it find the root cause. It will likely find a lot of potential causes, e.g. because its lacking about expected misleading log messages which were always there. Context is key, e.g. by augmenting the prompts with Retrieval Augmented Generation (RAG), Model Contex Protocol connections to tools (MCP) and providing a body of expert knowledge („ignore error message XY, its always there“).
* talking about trivial bugs, every software engineer incl tester knows that a majority of bug tickets is, in fact, trivial in some sense. There are duplicates, flukes, layer 8 problems, known limitations, etc. Wading through those is a major source of frustration and conflict, and LLMs have a huge potential to help here.
9. Reporting, Analysis & Feedback
Scope: Handles what happens after execution. Here, test results are aggregated, trends are analyzed, coverage metrics are put together, failures are clustered, flakiness statistics are gathered. Here, management, process customers and project-external customers are coming in as consumers, additional to the (often neglected) internal engineering workforce. While former layers detect failures, this one interprets them and puts them in context.
Pragmatic opportunities for cross-project alignment: The good thing is, that on this level we are clearly outside the area where project-specific tooling is required. Standardization here doesn’t (or does barely) constrain testing tooling. Hence, this is one lowest risk, highest return-on-investment layer for alignment.
Obviously, the way the reports are aggregated can be aligned in a cross-project manner. Dashboards which show cross-project data yet are possible to be filtered down to each project’s or sub-project’s slice can be very instructive for (project) management. If we exclude Defect Management but focus on actual test results, a precondition is to have aligned terminology, taxonomy and understanding of testing across projects, closing the loop to section Test Intent and Scope (aka Test Strategy).
Naturally, the focus of consumers will be on failed test cases more than passed ones. A unified failure taxonomy can contribute to align, too: Whether it is a product defect, a test tool defect (not relevant for customers), data defect, environment defect, flakiness, timing/performance degradation can make a huge difference.
It helps to agree on definitions, not thresholds first: What is a pass rate, how are process time intervals like „mean time to detect“, „mean time to repair“ defined, how are flakiness rates determined and coverages calculated.
Closing words
I have been pondering about this topic for many months, and I am glad I finally have put all my thoughts in words and a graphic:
I am looking forward to feedback. I am sure my evaluations are not globally agreeable, so I would be happy to enter a constructive discussion.
I had a weird issue today connecting via the VS Code extension Native Debug to a qemu instance. It was giving:
Visual Studio Code
Failed to attach: Remote target doesn't support qGetTIBAddr packet (from target-select remote :1234)
[Open 'launch.json'] [Cancel]
That sounded like gdb/native debug is expecting a feature qemu is not offering; however, just the day before it ran successfully – so what happened? Unfortunately and coincidentally, I did some housekeeping a few hours before, so my suspicion was that I somehow uninstalled some facilities, like Windows SDK or so. After 2 hours trying to reproduce my earlier setup, checking older versions of qemu, gdb and native debug I almost gave up, when I stumbled upon this via Google: https://github.com/abaire/nxdk_pgraph_tests/blob/main/README.md?plain=1#L187
NOTE: If you see a failure due to "Remote target doesn't support qGetTIBAddr packet", check the GDB output to make sure
that the `.gdbinit` file was successfully loaded.
Now, of course I checked the gdb output before, but besides some warnings nothing appeared suspicious. The link made me re-check, and indeed there was this:
undefinedBFD: reopening /cygdrive/c/Users/Jakob/Documents/workspace/os-series/C:\Users\Jakob\Documents\workspace\os-series\dist\x86_64\kernel.bin: No such file or directory
That appeared new on second thought, and I removed following line from my VS Code’s launch.json
"executable": "dist/x86_64/kernel.bin",
That made it work again. At least partially, of course now the info to the executable is missing, but I have the feeling this is a minor thing to fix.
Addition (Nov 11th):
I have two additions to make. First it seems reader Piotr found the actual proper solution to this, see his comment below. After setting „set osabi none“ in .gdbinit I can indeed use gdb as before. This setting makes gdb not assuming any operating system ABI, which makes sense when you code your own OS from scratch. Thank you so much Piotr!
Second, just fyi and in case someone has similar issue but the aforementioned solution doesn’t work for some reasons, here is tzhe workaround I used till Piotr came for the rescue. As written above, removing the „executable“ line from the launch.json made gdb work, but of course now the executable and its debug symbols are missing, so setting breakpoints from the UI didnt work. After much tinkering I realized that adding the executable later during the debugging session helped. So what I did was adding a hardcoded breakpoint in the very beginning of my test object. When this breakpoint was hit, some commands were executed, of which adding the kernel as symbol file is the most important one. Also I had to add another breakpoint inside this command, which made gdb reload all other breakpoints from the UI, too.
b *0x100018
commands
add-symbol-file dist/x86_64/kernel.bin
b isr_common_stub
end
This worked with the caveat, that each debugging session halted at this first hardcoded breakpoint and I had to manually continue once. It was an acceptable workaround, but I am happy today Piotr gave a proper solution.
I still have no clue what exactly made this issue pop up; as mentioned I blame my „housekeeping“ activities, which were too many to reproduce the exact root cause.
As written before, I really like the regular updates provided by Thoughtworks in their Technology Radar. My focus is on the applicability of techniques, tools, platforms and languages for automotive software, with a further focus on embedded in-car software. Hence, I am ignoring pure web-development and machine learning/data analytics stuff which usually makes a huge portion of the whole report. Recently, its volume 29 has been published. Let’s have a look!
In the techniques sector, the topic lightweight approach to RFCs has made it to the adopt area, meaning there is a strong recommendation to apply it. During my time at MBition, Berlin, I became exposed to a talk by Paul Adams on YouTube via my colleague Johan Thelin, which Paul later also gave during an all-hands event of our project:
Hence, the RFC thing very well resonates with me. It has been my style of creating documents about strategies, concepts, plans and very early requesting feedback from peers to check if the general direction is correct, and to finalize it later. Much what software engineers are used to do in Pull Requests, such scheme can and should be applied to more areas in a systematic manner. Architecture is one obvious area, but it can also be applied in many other areas. Confluence and similar collaboration platforms offer great inline commenting capabilities to discuss about any controversial aspects of a document and sort them out.
2.5 years ago I wrote about Dependency updates with Renovate. In the blip automatic merging of dependency update PRs the authors argue in favor of automatic merging of bot-generated dependency-updates. What can I say, makes total sense. Till today I have manually merged the pull requests created by the bot, but now I just let it automatically do that – of course only after a successful pipeline run. With renovate its as simple as adding "automerge": true to the renovate.json in each repo.
In tracking health over debt the authors describe a notion to focus more on the health of a sw system than tracking its (technical) debt. Its a worthwile approach, since focussing on debt means tracking an often ever-growing list. In my experience, some debt often gets obsolete, and some debt which was fiercely discussed when it was „implemented“ later is turning out significantly worse or better. Instead, tracking the health of the system as primary measure where to act at any time may yield better results in the overall long game.
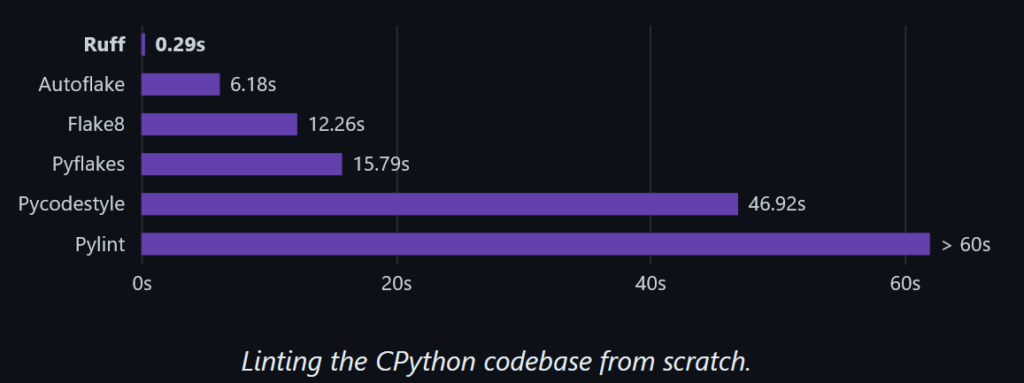
In the tools sector, Ruff is recommended as a successor to the famous Python linter Flake8. Implemented in Rust, it seems to offer superior performance while still providing similar rule coverage:
A quite untypical entry (at least to my knowledge) is the mention of DevEx 360, a survey tool focussed on identifying impediments and potential improvements among the dev team.
Our platform engineering teams have used DX DevEx 360 successfully to understand developer sentiment and identify friction points to inform the platform roadmap. Unlike similar tools, with DX DevEx 360 we’ve received a response rate of 90% or above, often with detailed comments from developers on problems and ideas for improvements. We also appreciate that the tool makes results transparent to engineers in the company instead of just managers and that it enables team-by-team breakdown to enable continuous improvement for each team’s context.
This was it already for „my“ scope of the tech radar. This time around, the tech radar contained a looot of new entries and updates in the AI area, around GPT and LLMs. Certainly interesting, but nothing I have much experience and applications (yet).
Disclaimer: Im Jahr 2018 bat mich ein Bekannter, der damals Mitglied des Deutschen Bundestags war, um eine kurze Einschätzung zur Thematik „5G Mobilfunk im Automobilbereich“. Er wusste, dass ich zu Fahrzeug-zu-Fahrzeug-Kommunikation promoviert wurde, und wollte meine Einschätzung sowie mögliche politische Stoßrichtungen kennenlernen. Das Dokument war weder offiziell noch zur Veröffentlichung bestimmt, und mir ist nicht bekannt inwiefern es weiterverwendet wurde. Nach sieben Jahren habe ich entschlossen, es am 25. Januar 2025 hier zu dokumentieren (dieser Blogbeitrag ist rückdatiert zum Termin des Abschlusses der Erstellung). Vielleicht interessiert den einen oder anderen meine damalige Einschätzung und die Verlässlichkeit meiner Prognosen.
Vorwort (25. Januar 2026): Ich habe diesen Artikel im August 2018 für die Mitgliedszeitschrift der Burschenschaft Alemannia Stuttgart verfasst.
Im letzten Jahr erstand ich auf einem Flohmarkt in Stuttgart-Ost gebraucht das Buch „Stuttgart zur Zeit des Nationalsozialismus“ von Roland Müller. Das Thema interessiert mich und das Geleitwort des zum Zeitpunkt der Veröffentlichung amtierenen Oberbürgermeisters Manfred Rommel ließ mich auf eine lehrreiche Lektüre hoffen.
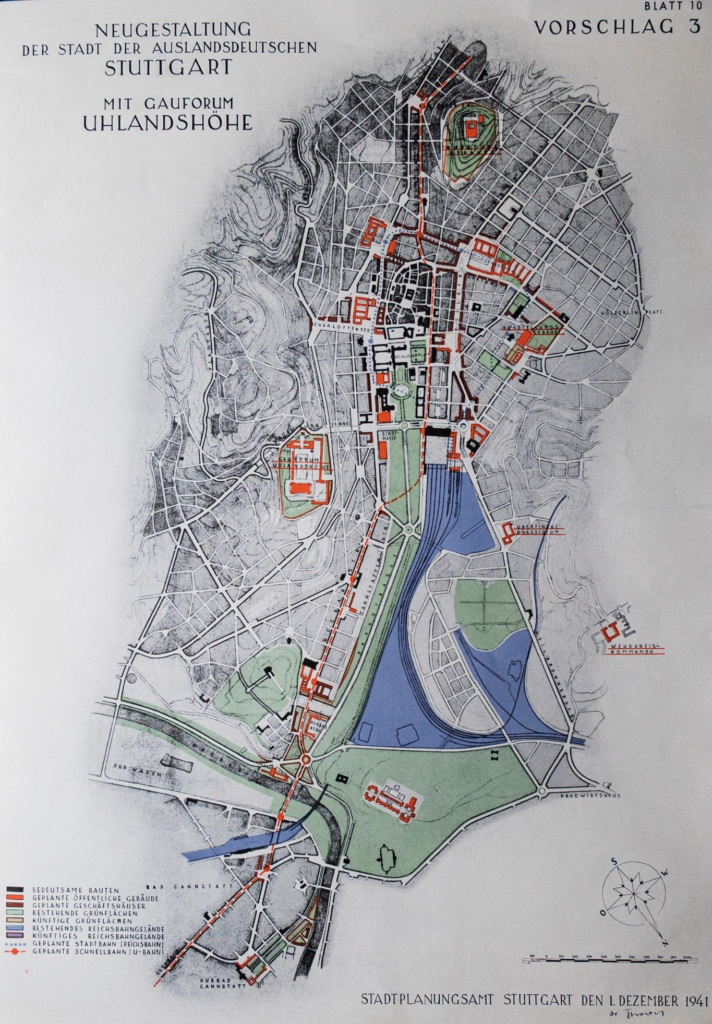
Zu Hause angekommen, blätterte ich in dem knapp 700-Seiten-Schmöker, und da fiel mir sogleich zufällig ein Bild ins Auge. „Das ist doch die Uhlandshöhe“, dachte ich mir, aber dann doch wieder nicht. Die Bildbeschreibung und der zugehörige Text klärten mich auf:
Stuttgart erhielt am 11. September 1936 den NS-Ehrentitel „Stadt der Auslandsdeutschen“. Wikipedia: „Diese Beinamen konnten auf eine besondere Bedeutung der Stadt für die Entwicklung des Nationalsozialismus verweisen oder auf die historische Bedeutung der Stadt hindeuten.“ Aus heutiger Sicht naheliegender dürfte ein solcher Ehrentitel für die Städte Nürnberg („Stadt der Reichsparteitage“) und München („Hauptstadt der Bewegung“) sein. Der Ehrentitel Stuttgarts kommt daher, da hier das Deutsche Ausland-Institut (DAI) ansässig war. Seine Hauptaufgabe war die Dokumentation aller deutschen Volksgruppen im Ausland. (Heute gibt es übrigens eine Nachfolgeinstitution, das Institut für Auslandsbeziehungen, untergebracht im selben Gebäude wie das Cafe Planie zwischen Karlsplatz und Charlottenplatz) Der Oberbürgermeister Stuttgart von 1933 bis 1945, Karl Strölin, war Vorsitzendes des DAI und forcierte in Berlin die Verleihung des Ehrentitels. Mit involviert war auch Paul Bonatz, den Stuttgarter bestens bekannt als Erbauer des Stuttgarter Haupbahnhofs.
Im Folgenden gebe ich die relevanten Textstellen aus dem Buch wider (S. 355-358):
„Neugestaltung der Stadt der Auslandsdeutschen
Mitten im Kriege, als das Bauen auf den Luftschutz und wenige kriegswichtige Notwendigkeiten beschränkt war, legte das Stadtplanungsamt eine Denkschrift über die „Neugestaltung der Stadt der Auslandsdeutschen Stuttgart“ vor. Eine Umgestaltung der Innenstadt war schon vor dem Krieg erörtert worden. Sie sollte die Stadt der Motorisierung anpassen und durch repräsentative Gebäude dem „Stil der neuen Zeit“ sichtbaren Ausdruck verleihen.
Strölin hatte sich entgegen einem Erlaß des Reichsinnenministers mit Reichsstatthalter Murr auf eine Fortsetzung der Planungen verständigt. Die aktuellen Probleme schufen laut Strölin die Voraussetzungen, um »in aller Ruhe und mit der gebotenen Gründlichkeit“ in ein Planungsstadium einzutreten. Im Frühjahr 1939 beauftragte er Baudirektor Ströbel vom Stadtplanungsamt, sich ausschließlich der Arbeit an den Umgestaltungsplänen zu widmen. Die völlig veränderten Bedingungen für die kommunale Verwaltung nach Kriegsbeginn unterbrachen diese Arbeit. Doch nach dem siegreichen Ausgang des Westfeldzugs schien Strölin ein Neubeginn geboten, um den äußeren Erfolgen sichtbaren Ausdruck zu verleihen: „Im Hinblick auf die günstige Entwicklung der Kriegslage ist es nunmehr an der Zeit, die Fragen der Umgestaltung der Innenstadt von Stuttgart wieder tatkräftig aufzunehmen. “ Stadtrat Schwarz hatte als Technischer Referent die Gesamtleitung, die Sachbearbeitung oblag Ströbel.
Der Sieg im Westen leitete auf höchster Ebene eine neue Planungsphase ein. Von irgendwelchen Stuttgarter Plänen wußte man in Berlin allerdings nichts. Dies war angesichts des Engagements der Stadtverwaltung zum Beispiel in auslandsdeutschen Angelegenheiten doch einigermaßen erstaunlich. In einem Bericht Speers vom Februar 1941 hieß es lediglich: „Erste städtebauliche Ideen vor Jahren vorgetragen, aber seitdem keine weitere Kenntnis erhalten.“ Dabei hatte die Stadt im Mai 1940 neue Gutachten in Auftrag gegeben und Architekten und Verkehrsplaner, darunter die Professoren Wetzel, Tiedje, Pirath und Alker, eingeladen. Die Gutachter näherten sich in unterschiedlich intensiver Weise den offiziösen Vorstellungen Hitlers an. Dieser hatte für die Neugestaltung von Gauhauptstädten die Errichtung eines Gauforums mit den Parteibauten, einem Kundgebungsplatz und einem Glockenturm gefordert: Die Stadt war mit den Gutachten, die im Sommer 1941 vorlagen, nicht voll zufrieden. Besonders umstritten waren der Standort des Gauforums und eine etwaige Verlegung des Hauptbahnhofs nach Cannstatt, um die bebaubare Fläche in der Innenstadt entscheidend zu vergrößern.
Strölin bat seinen Gewährsmann Bonatz um eine zusammenfassende Beurteilung. Dieser wollte (den von ihm geplanten) Hauptbahnhof an seinem Standort belassen und die Uhlandshöhe mit dem Gauforum bekrönen. Bonatz schrieb von einem vollem Erfolg seiner Vorschläge bei der Stadt als Ergebnis einer dreißigjährigen Arbeit. Zugleich attackierte er Speers „babylonische“ Vorhaben in Berlin und München. Diese Richtung habe in Stuttgart Alker vertreten, der mit seiner „öden Achse“ aber nicht zum Zuge gekommen sei. Nun mußte der Entwurf, wie Bonatz wußte, „noch beim Gauleiter durchgekämpft werden“. In dieser Auseinandersetzung mit Murr schlug die Geburtsstunde besagter Denkschrift, als sich das Stadtplanungsamt bereit erklärte, „in verschiedenen Großfotos das Gauforum“ in seinen Varianten darzustellen. Murr hatte nämlich gegen die Uhlandshöhe votiert; nachdem das Rundfunkgebäude auf der Karlshöhe und das Generalkommando auf dem Weißenhof vorgesehen waren, hielt er es für falsch, „auf alle Höhen solche monumentalen Gebäude zu stellen.
Erst im Sommer 1942 war die Denkschrift schließlich fertig. Sie war nicht Ausdruck städtischer Vorstellungen, sondern zusammenfassendes Resultat einer jahrelangen Diskussion. Ziel sei es, so das Vorwort, „nach den Grundgedanken der nationalsozialistischen Weltanschauung die Bauten der Gemeinschaft zum herrschenden Element der städtebaulichen Gestaltung zu machen“. Eine Verwirklichung dieses Vorsatzes hätte eine Abkehr von der bisherigen Baupolitik bedeutet. Einleitende Bemerkungen über das „Raumproblem in der Großstadt“, über die Verkehrsprobleme und die „städtebauliche Neugestaltung der Stadt Stuttgart“ waren knapp und allgemein gehalten. Die Raum- und Verkehrsprobleme, so hieß es weiter, ließen sich ohne Zwang großzügig lösen. Angesichts der komplizierten Verhältnisse, die bei der mehrjährigen Debatte zutage getreten waren, bedeutete diese Formulierung einen propagandistischen Euphemismus.
Analog zu den früheren Verhandlungen wurde zunächst eine Verlegung des Hauptbahnhofs erörtert. Sie sei wünschenswert, im Augenblick aber nicht zu realisieren; mit einer Teilverlegung sei jedoch nichts gewonnen. Ziel der Verkehrsplanung sei die Schaffung eines leistungsfähigen Innenstadtrings mit einer geeigneten Verbindung zu den Ausfallstraßen und zur Reichsautobahn. Auf der Ostseite des Talkessels genüge die Neckarstraße den Bedürfnissen, nachdem mit dem Durchbruch an der Holzstraße die südliche Erweiterung in die Wege geleitet worden war. Auf der Westseite sah der Plan einen Durchbruch der Roten Straße vor, die auf 40 Meter verbreitert werden sollte. Die Königstraße als mittlere Verkehrsachse in der Innenstadt sollte entlastet werden. Größere Schwierigkeiten warfen die Querverbindungen auf. Die südliche Tangente Gartenstraße-Wilhelmsplatz war zu eng, angeregt wurde daher ein Durchbruch bei der Ernst-Weinstein-(Sophien-)Straße. Die mittlere Verbindung von der Adolf-Hitler-Straße (Planie) zur Schloßstraße schien den Planern „angesichts der vielen im Wege stehenden öffentlichen Gebäude: des Prinzenbaues, des Neubaues der Deutschen Arbeitsfront, des Landesgewerbemuseums und der Gebäude am Stadtgarten kaum zu verbessern“ Der überlastete Knotenpunkt vor dem Hauptbahnhof sei nur mittels einer Unterführung zu entwirren. Als Ausfallstraßen kamen nach Osten der im Bau befindliche Wagenburg-Tunnel und nach Westen ein neuer Kräherwald-Tunnel vom Hölderlinplatz aus in Frage. Zusätzlich war in die Denkschrift die von Bonatz vorgeschlagene Parkstraße durch den Rosensteinpark „ähnlich der Ost-West-Achse in Berlin“ aufgenommen. Sie sollte von den Cannstatter Kuranlagen bis zum Neuen Schloß führen und war als Parkstraße mit den großen Achsen überhaupt nicht zu vergleichen. Die Stadtverwaltung lehnte diese Parkstraße, die die letzte größere innerstädtische Grünfläche zerschnitt, ab. In die Denkschrift war sie als Ehrenbezeigung gegenüber Bonatz aufgenommen worden, der seinerseits mit dieser Straße dokumentiert hatte, wie wenig er von den großen Achsen eines Speer hielt. Der Anregung von Schwarz folgend sollten die Hauptlinien der Straßenbahnen auf Schnellverkehr und die Linie vom Südheimer Platz bis nach Bad Cannstatt als U-Bahn geführt werden. Auch die Stadtbahn-Schleife war in der Denkschrift erwähnt: „Stadtbahn und Längs-U-Bahn aber werden diejenigen Verkehrsmittel sein, welche in der Lage sind, den Verkehrsanforderungen für alle Zeiten gerecht zu werden.
Der zweite Teil der Denkschrift widmete sich der städtebaulichen Neugestaltung. An erster Stelle stand das Gauforum. Neben dem Standort auf der Uhlandshöhe wurden das Bollwerk sowie — bei einer Verlegung des Hauptbahnhofs — das Rosensteingelände vorgestellt. Die Stadt favorisierte die Uhlandshöhe. Während ein „Stadtforum“ mit dem Rathausneubau im Bohnenviertel plaziert war, hingen die Standorte für die übrigen repräsentativen Bauten entscheidend vom Gauforum ab. Entlang der Neckarstraße war die Kulturmeile vorgesehen; Murrs Wunsch nach einem Haus der Musik fand hier Berücksichtigung. Während die Pläne für ein Generalkommando und ein Rundfunkgebäude sich im Planungsstadium befanden, deutete die Denkschrift weitere Großbauten — Ausstellungsräume beim Stadtgarten, eine neue Stadthalle an der Neckarstraße sowie eine Fülle öffentlicher Gebäude, an der Spitze Neubauten der Technischen Hochschule und einer Ingenieur-Offiziers-Akademie — lediglich an. „So wünschenswert und notwendig die Maßnahmen zur Verbesserung der Verkehrsverhältnisse auch sein mögen, so muß man sich doch darüber vollkommen im klaren sein, daß die Bekämpfung der Wohnungsnot die erste und vordringlichste Bauaufgabe nach dem Kriege darstellen wird.(…) Wenn diese große Aufgabe des sozialen Wohnungsbaues nach dem Kriege gelöst sein wird, dann werden zweifellos die Verkehrssanierungen in der Innenstadt an erster Stelle der durchzuführenden Neugestaltungsmaßnahmen stehen.“
Gemessen am Verlauf der jahrelangen Diskussion war dies die Prioritätenliste der Stadtverwaltung. Murr, dem die Denkschrift gewidmet, vor allem aber zur endgültigen Entscheidung vorgelegt wurde, gab seine Wünsche nicht bekannt. Lediglich vom Innen- und Wirtschaftsminister erfolgte eine beiläufige Reaktion. Er fand Inhalt und Darstellung „sehr interessant“, vermißte jedoch eine großzügige Lösung der Markt- halle. Der romantische Marktbetrieb passe nicht zu einer Großstadt, befand Schmid, und schlug eine Großhalle beim Vieh- und Schlachthof sowie dezentralisierte kleinere Hallen vor. Wenngleich die Stadtverwaltung dem Wohnungsbau Vorrang einräumte und die Gesamtplanung auf Jahrzehnte angelegt war, so drohte Stuttgart doch eine rasche Umgestaltung als „Ausdruck nationalsozialistischer Weltanschauung“. Die Zukunft der Neugestaltungspläne war 1942 allerdings höchst ungewiß. Strölin notierte resigniert: „Die Denkschrift für die Neugestaltung der Stadt Stuttgart ist nun nach unendlichen Schwierigkeiten endlich fertig. Aber die Probleme, die wir damals erörtert haben, scheinen nun in so weite Ferne gerückt, daß man den Eindruck hat, die ganze Arbeit ist umsonst gemacht.“
Interessante Entwicklungen, die so zumindest auf der Uhlandshöhe glücklicherweise nicht Realität wurden. Was die Forderungen nach radikalen Umbauten in der Innenstadt anbelangt, wurden sie in anderer Form nach Bombenkrieg und Ideologie der autofreundlichen Stadt leider auf ganz bedrückende Weise verwirklicht.