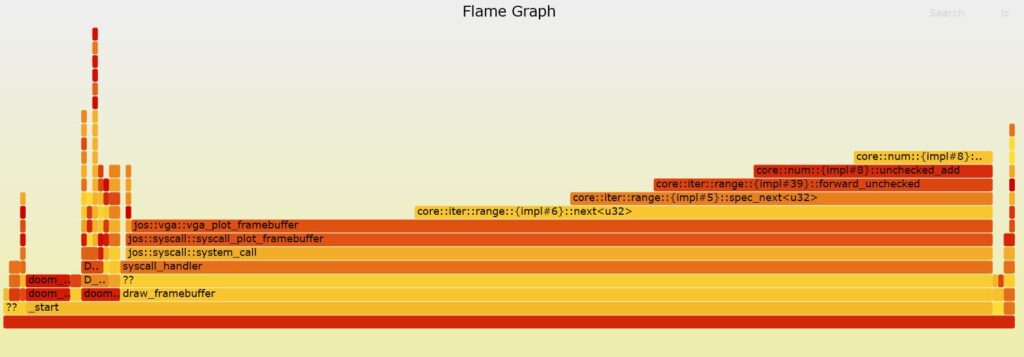
[No tokens have been burned to write this article 🙂 ]
Even though I am subject to some skepticism on the rise of LLM/GenAI, its impact on software engineering practices (must read: very lucid article on the impact of AI code generation on the whole software engineering value chain, from a lean perspective) and the whole of society, I am trying to stay on top of whatever new possibilities arise and not only consume huge amounts of YouTube videos, instead also try to apply them on my projects in work and private. I do not consider myself a power user, I am not burning through Claude Pro Max 20x plans, and I am mostly sticking to my VS Code, which seems to follow the more progressive agentic IDEs in a reasonable pace.
A very nice effect is that LLMs enable myself as a busy software engineering manager to still come back to the occasional helpful helper script every once in a while. I have been doing this without LLMs, but my typical work-related one-shot single purpose script output has increased over the last 2 years or so.
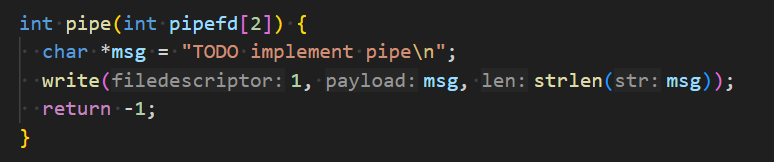
Learning 1: Context: In my bigger projects, which existed before GenAI got a thing, the first thing I am doing is to let it generate a technical and/or product documentation. I put a focus on software quality aspects which are important to me, like a very high test coverage. I am confident that this helps me to keep the codebase somewhat under control even if code output by LLM increases massively.

[Excerpt]
### Docker
Multi-stage build:
1. **Builder** (composer:2.9.5): installs PHP dependencies (`--no-dev`)
2. **Runtime** (php:8.5.0-apache): copies app + vendor, generates `swagger/swagger.json` via `openapi` CLI, enables `mod_rewrite`, installs `pdo_mysql` extension, uses production `php.ini`
### Acceptance Tests
Browser-based tests using PHPUnit + Selenium WebDriver (Chrome headless).
### Static Analysis & Quality
Phan, PHPMD, PHP_CodeSniffer, Infection (mutation testing), Trivy (CVE scanning), Schemathesis (API contract testing).
## Noteworthy Details
- **No authentication**: All endpoints are public. Security relies on random hex IDs being unguessable and infrastructure-level controls
- **No framework**: Raw PHP with manual URI parsing and method dispatch
- **SQL injection protection**: All queries use PDO prepared statements
- **OpenAPI auto-generation**: Swagger spec generated at Docker build time from PHP attributes
- **Sentinel dates**: Deadline of `2000-01-01` means "no deadline" — frontend filters this out
- **Date handling**: ISO 8601 on API boundary, MySQL datetime in storage, conversion in Gateway layer
Putting this documentation (and policies) in a defined place will always include them in the prompt (instructions.md under .github/instructions). With Claude Skills and the like there is a neven more versatile option to carry this out. I recently started to employ this in work projects.
Learning 1.5: Do not forget to review and push your agent to obey your project policies. It can easily happen that for a small additional feature, an agent may attempt to replace your complete architecture and framework. This has gotten better lately, but still may happen very unexpectedly.
Learning 2: Planning before Coding. Like with human coding, thinking about the given task in depth and first making a solid plan also helps to produce better implementations from the start. This refinement can
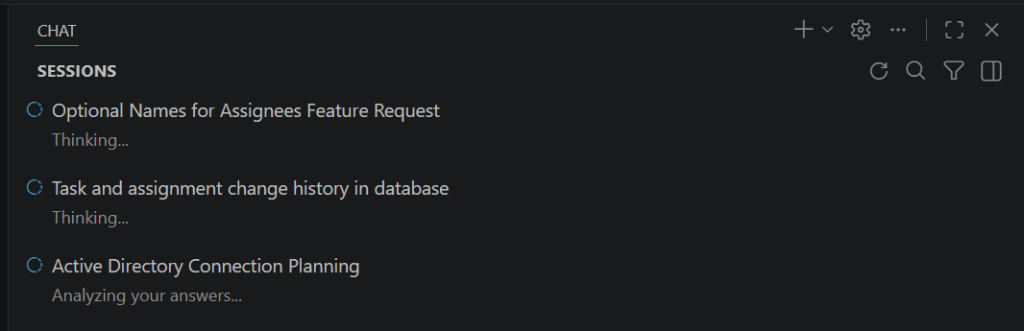
Learning 3: Parallelize: In the screenshot below you can see 3 sessions running in parallel. This takes quite a mental load. I am yet undecided if I really can handle more than one thread without causing too much turmoil in my project.
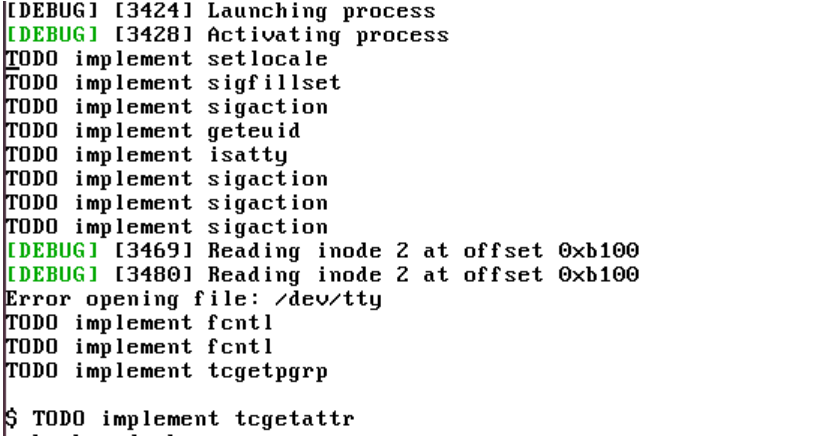
Learning 4: Read the responses: At least skip over them. Sometimes it does something what you want, but leaves some things open. Just while writing this article I almost missed a „If you want, I can also add a small backend test or update the task creation API flow to fully validate the new field.“ Yes, please!
Learning 5: Tool calling: I have come to pretty much trust any tool calls in the context of my projects from my IDE. At work, we use VS Code dev containers, which seem to be a reasonable protection. Of course, I have read the horror stories around OpenClaw, but I am not yet commiting my full life’s data and resources, and having a proper version control makes me belief its ok for now.
Learning 6: GenAI is considerably better than me in design. For my (still unpublished) private pet project of the last 7 years or so, it did one shot a massively better UI design. Well actually, it even proposed multiple designs though which I could cycle via a toggle button. For sure, professional UI/UX designers will have a word on this, but their skills are not my baseline.